

{kind=link}
{kind=link}
{kind=link}
名词分布是人类语言的不变量吗?——以德语书面语中名词分布为例
引用本文
李媛, 段庭辉, 刘海涛. 名词分布是人类语言的不变量吗?——以德语书面语中名词分布为例[J]. 浙江大学学报(人文社会科学版), 2020,5(6): 39-48
Li Yuan, Duan Tinghui, Liu Haitao. Is the Distribution of Nouns an Invariant in Human Languages?— An Investigation Based on Written German Corpora[J]. JOURNAL OF ZHEJIANG UNIVERSITY (HUMANTIES AND SOCIAL SCIENCES), 2020,5(6): 39-48
DOI:10.3785/j.issn.1008-942X.CN33-6000/C.2019.06.231
Li Yuan, Duan Tinghui, Liu Haitao. Is the Distribution of Nouns an Invariant in Human Languages?— An Investigation Based on Written German Corpora[J]. JOURNAL OF ZHEJIANG UNIVERSITY (HUMANTIES AND SOCIAL SCIENCES), 2020,5(6): 39-48
Permissions
Copyright©2020, 浙江大学学报(人文社会科学版)
浙江大学学报(人文社会科学版) 所有
名词分布是人类语言的不变量吗?——以德语书面语中名词分布为例
[作者简介] 1.李媛(https://orcid.org/0000-0002-3555-4965),女,浙江大学外国语言文化与国际交流学院教授,博士生导师,哲学博士,主要从事德语语言学、德语教学理论与实践研究; 2.段庭辉(https://orcid.org/0000-0002-3324-0938),男,德国耶拿大学日耳曼语言学系博士研究生,主要从事语料库语言学、二语习得研究; 3.刘海涛(https://orcid.org/0000-0003-1724-4418)(通信作者),男,教育部长江学者特聘教授,浙江大学求是特聘教授,博士生导师,文学博士,主要从事计量语言学、依存语法、语言复杂网络、语言政策与语言规划研究。
摘要
此前对人类自然语言中词类分布的研究显示,不同语言中名词所占比例相对固定。德语中名词所占比例是否也符合这一普遍规律?通过对三个大型德语语料库进行研究发现:首先,德语书面语中的名词占比约为38%,尽管德语复合名词比例高、名词化结构多,但其名词占比同英语以及其他语言中的名词占比大致相当,从而进一步证实了人类自然语言中名词占比具有普遍规律这一结论;其次,不同文体中名词及其各子类的占比有所差异,而这一差异由文体特征决定,并且具有跨语言的相似性;最后,时间因素与文体类型均对名词各个子类占比有显著影响,但名词总体占比未受二者影响。综上,可以进一步证实名词分布是人类语言的不变量这一结论。
关键词:
德语; 名词分布; 语料库; 计量特征; 文体; 历时变化
Is the Distribution of Nouns an Invariant in Human Languages?— An Investigation Based on Written German Corpora
Abstract
Hudson indicates that the proportion of nouns in written English is about 37%. Since then, many other languages haven been studied in this respect, finding out that the proportion of nouns in all human languages is an invariant. German and English have differences in word formation, though they both belong to the West Germanic language subfamily. As for nouns, on the one hand, German has a larger proportion of compound nouns, resulting in intensive information, thus the total quantity of its nouns could be relatively smaller than that of other languages; on the other hand, nominalized structures are common in German, which may cause a larger proportion of nouns in comparison with other languages.
Does German conform to the universal law of language? We try to answer this question based on three large-scale corpora of German: The DWDS-Kernkorpus consists of texts of different genres from the 20th Century and has more than 100 million words in total; The Deutsches Textarchiv (DTA) is a diachronic corpus of written German and contains about 150 million words from texts of the same genres as DWDS-Kernkorpus; The TüBa-D/Z treebank is a German newspaper corpus with more than 1.5 million words, containing 3 644 mainstream newspaper articles of Die Tageszeitung from 1989 to 1999. In order to make the results comparable, we adopted the same classification criteria for nouns and the part-of-speech tag sets suggested by Hudson. The result shows that the proportion of nouns in all three corpora of written German is about 38%. Thus, the above-mentioned hypothesis is corroborated.
Furthermore, we studied the relationship between the proportions of nouns in different genres. Differences exist between different genres in terms of the proportions of subclasses of nouns including common nouns, proper nouns and pronouns. While common nouns are larger in proportion in informational texts, imaginative texts have a larger proportion of pronouns. This result also complies with that of Hudson.
Little work has previously been conducted with the diachronic development of language. In this study, we additionally explored the relationship between time and the proportion of nouns (and its subclasses) by analyzing texts from 1500 to 1950. While no big change of the total proportion of nouns in the last five hundred years was observed, there is a shift between the proportion of common nouns and that of pronouns. The proportion of common nouns has been increasing continuously from 14.02% at the beginning of 16th Century to about 24% in the 20th Century, whilst the proportion of pronouns has decreased from 16.66% to 10%. To our best knowledge, this diachronic tendency hasn’t been addressed so far. We argue this tendency is caused by the social and technical development as well as the evolution of the language itself.
In conclusion, this study corroborated the hypothesis that the distribution of nouns in all human languages is an invariant. The proportion of subclasses of nouns in written German varies among genres and has changed a lot with time, although the general proportion of nouns remains the same. Moreover, we observed a continuous increase of the proportion of common nouns and a correspondingly decrease of the proportion of pronouns in written German in the last five hundred years. This interesting finding offers a new perspective to language evolution and quantitative linguistic research and deserves further studies.
Keyword:
German; distribution of nouns; corpora; quantitative linguistic characteristic; genres; diachronic tendency
一、 引 言
词类分布是语言的一个重要不变量, 它不仅能表现语言的共性, 也能反映语言的特点[1]。Hudson认为, 随机选取的词属于某一特定词类的概率似乎是有规律的, 但这一点我们却完全没有意识到[2]339。在任何一种语言中, 名词均数量庞大。名词能够表达自然界和人类社会各种事物的名称, 具有丰富的语法功能, 在语言的基本单位之一句子中发挥着不可或缺的作用。此外, 其他词类的占比均与名词占比相关[3]。因此, 名词分布研究的重要性不言而喻。
Hudson在对两个大型英语语料库研究的基础上指出, 名词在英语书面语中的比例约为37%[2]。刘海涛对汉语的研究结果显示, 汉语中名词占全部词数的比例为39.29%[4]。Liang和Liu对比了包括德语在内的七种语言中名词的占比, 发现在所有七种语言中, 名词所占比例均约为37%[5]。这项跨语言研究在一定程度上有助于我们理解名词占比在人类语言中的稳定性, 但由于其语料、语体、统计方法的局限性, 并没有完全回答名词分布的稳定性问题。此外, 研究虽引用了前人得出的名词占比与文体有关的结论[3]2, 但并未使用数据验证, 也未探讨还有哪些因素可能会对名词占比产生影响。
名词分布是人类语言的不变量吗?为了更好地回答这一问题, 我们尝试寻找与英语语料库更具可比性的德语平衡语料库, 并采用相同的统计方法对其进行研究。之所以研究德语, 是因为德语和英语虽同属印欧语系西日耳曼语支, 但两种语言在构词形式上不尽相同。就名词而言, 一方面, 德语的复合名词比例高, 信息相对集中, 可能导致名词的总量小于其他语言; 另一方面, 德语尤其是科技德语中的名词化结构多, 名词占比也许会因此高于其他语言。基于这些原因, 我们认为采用德语语料库对德语名词分布进行研究, 有助于理解名词占比在人类语言中是否稳定不变的问题。而为了准确回答这一问题, 需要对以下三个方面进行深入研究:德语中名词的占比是多少?这一比例的高低是否与文体相关?时间因素与名词占比有关系吗?
因此, 本文基于德国柏林— 勃兰登堡科学院的大型语料库DWDS-Kernkorpus、Deutsches Textarchiv(DTA)以及图宾根大学计算机语言学研究所的依存树库Tü Ba-D/Z, 对德语书面语中的名词所占比例进行研究, 并且针对不同文体和不同时期语料之间的差异进行探讨。DWDS-Kernkorpus包含20世纪不同文体的德语书面语及口语语料。由于本文的研究重点是书面语, 在进行统计时将口语语料的数据排除在外。该语料库书面语部分的单词总数超过1亿, 包含文学作品、应用文、学术论文和报刊文章四类不同文体[6]。DTA收录了1473年到1969年间共3 527篇语料, 包含与DWDS-Kernkorpus语料库对应的四种文体, 总词数约1.5亿[7]。Tü Ba-D/Z语料库的语料来源为1989年到1999年间发表于德国主流媒体Die Tageszeitung(《日报》)上的3 644篇文章, 总词数约为150万[7]。
二、 德语中名词的占比
Hudson[2]对名词的统计基于Brown[8]和LOB[9]两个英语语料库。其中Brown语料库收录了1961年在美国出版和发行的500篇文章, 共计约100万个单词, 涵盖了15类不同的文体; 而LOB语料库是对应Brown语料库的英式英语语料库, 收录了1961年在英国出版和发行的500篇文章, 规模同样在100万个单词左右, 涵盖了与Brown语料库相对应的15类不同文体。Hudson对名词占比的统计基于Francis等[8]和Johansson等[9]所提供的原始数据, 其统计结果如表1所示[2]332:
| 表1 Brown和LOB数据库中的名词占比 |
为了使我们的研究结果与Hudson[2]得出的结果具备可比性, 我们在对德语中名词的占比进行统计之前, 首先考察了Hudson对名词的界定。他在得出名词占比约为37%的结论时, 将普通名词、专有名词和代词都算作名词, 而这三个词类又各自包含多个子类, 其中普通名词包括词类标记符号为“ CD...” “ NN...” “ AP$” “ APS...” 的单词, 专有名词包括词类标记符号为“ NP...” “ NC” “ NR...” 的单词, 代词包括词类标记符号为“ P...” “ W...” “ EX” 的单词。以上词类标记符号的具体含义在Francis等[8]和Johansson等的研究[9]中有详细说明。
此外, 我们注意到, Hudson在其论述中没有说明是否将标点符号算作单词。为了澄清这一问题, 我们基于Francis等[8]和Johansson等[9]的原始数据对Hudson的统计结果进行了重新验证, 结果如表2所示:
| 表2 Brown和LOB数据库中的名词占比(不含标点和含标点) |
表2中, “ 占比1” 一列中的数据由名词的数量除以所有单词(不含标点符号)的数量得出, 根据这一标准, Brown语料库和LOB语料库的名词占比分别为36.75%和35.85%; “ 占比2” 一列中的数据由名词的数量除以所有单词(包含标点符号)的数量得出, 根据这一标准, Brown语料库和LOB语料库的名词占比分别为32.76%和31.40%。可以看出, “ 占比1” 中的数据与Hudson所统计出的数据(见表1)相符, 说明Hudson在进行统计时没有计入标点符号。
按照Hudson的统计方法和对名词的界定标准, 我们对DWDS-Kernkorpus(总单词数102 698 905)以及Tü Ba-D/Z(总单词数1 525 688)中的名词占比进行了统计, 并将统计结果同Brown和LOB语料库进行比较, 其结果如表3所示:
| 表3 四个语料库中的名词占比 |
由于两个德语语料库所采用的STTS标记集[9]与Brown和LOB语料库所采用的标记集不同, 我们在对STTS进行仔细分析的基础上找出了对应Hudson划分的三个名词子类的各个词类, 其中普通名词包括CARD、NN以及TRUNC, 专有名词包括NE, 代词包括PIAT、PIDAT、PIS、PPER、PPOSAT、PPOSS、PRELAT、PRELS、PRF、PWAT、PWAV、PWS。
根据Hudson[2]的描述, 他在统计名词时没有将this、that等指示代词统计进去, 其原因或许为Brown语料库和LOB语料库的词类标记集中没有对形容词性的指示代词和名词性的指示代词进行区分, 二者都被标记为DT(Determiner[9]12)。如在句子“ This apple is good.” 中, this为形容词性的DT, 并不能算作严格意义上的代词; 而在句子“ This is interesting.” 中, this为名词性的DT, 是严格意义上的指示代词。而在通行的德语词类标记集STTS中, 对形容词性的指示代词和名词性的指示代词进行了区分, 分别被标记为PDAT(形容词性指示代词)和PDS(名词性指示代词)[10]。为了同Hudson的划分标准保持一致, 我们在统计德语的代词时也没有将二者计入。
表3显示, 四个语料库中名词所占比例基本相当:两个德语语料库中名词所占比例分别为37.92%和38.02%, 两个英语语料库中名词所占比例分别为36.75%和35.85%。由此可见, 从名词占比来看, 德语和英语具有相似的词类分布特征, 符合人类语言的普遍规律。
三、 名词分布与文体的关系
在对表3进行细致观察后我们发现, Tü Ba-D/Z语料库中各个名词子类的占比与其他三个数据库差异较大, 其中普通名词和专有名词的比例都高于其他三个语料库, 而代词的比例明显低于其他三个语料库。由于Tü Ba-D/Z所包含的文体单一, 只收录了报刊文章, 我们猜测这是不同的文体特征所导致的差异。下面我们将对四个语料库中的不同文体进行归类, 进一步研究它们对名词所占比例的影响。
如上文所述, Brown语料库和LOB语料库都包含了15类不同的文体。其中报刊报道(Press: Reportage)、报刊社论(Press: Editorial)、报刊书评(Press: Reviews)、宗教类文章(Religion)、技能与爱好类文章(Skills and Hobbies)、民间传说(Popular Lore)、严肃文学(Belles Lettres)、传记(Biography)、纪念性文章(Memoirs etc.)、杂文(Miscellaneous)及知识类文章(Learned)被归并为信息类文体(INFORMATIONAL), 而其余的文体, 如通俗小说(General Fiction)、神话与侦探小说(Mystery and Detective Fiction)、科幻小说(Science Fiction)、冒险与西部文学(Adventure and Western Fiction)、浪漫与爱情故事(Romance and Love Story)及幽默文章(Humor)被归并为想象类文体(Imaginative)。Hudson[2]对这两大类文体中词类的分布情况进行了对比, 结果显示, 无论在Brown语料库还是LOB语料库中, 普通名词在信息类文体中的平均比例都比其在想象类文体中的比例高出约7个百分点。与此同时, 信息类文体中代词的比例则比其在想象类文体中的比例约低8个百分点。而专有名词在两大类文体中的比例基本一致[2]332(见表4)。
| 表4 英语普通名词、专有名词和代词在信息类文体和想象类文体中所占比例 |
为了考察上述差异是否在德语的不同文体中也存在, 我们将DWDS-Kernkorpus所包含的四个不同文体的子语料库也按信息类文体和想象类文体两大类进行拆分合并, 其中信息类文体包括应用文(Gebrauchsliteratur)、学术论文(Wissenschaft)和报刊文章(Zeitung), 想象类文体包括文学作品(Belletristik)。经统计, 名词各个子类在两类文体中所占比例如表5所示。
表5显示, 在德语书面语中, 普通名词在信息类文体中的比例为25.30%, 比其在想象类文体中的比例高出约7个百分点; 而代词在信息类文体中的比例则比其在想象类文体中的比例约低7个百分点, 只有想象类文体的一半。这一差异与Hudson所得出的英语书面语中两类文体之间的差异基本一致。信息类文本需要描述并传输信息, 所以需要更多使用普通名词, 特别是普通名词中多具抽象性的派生名词[11]。而想象类文体, 比如文学作品重在叙述情节, 由于情节的连贯性, 会较多使用代词指代前文提到的时间、地点和人物等, 加强文本各部分的衔接。对于这一现象, Francis等[8]、Biber[12]以及Tuldava[13]也做了类似的解释, 他们均指出, 典型叙事性文章的文体特征之一是“ 较多地使用人称代词” 。方梦之同样发现代词词频随着文体正式程度的降低而增加, 他比较了从美国商务出版局PB报告到短篇小说的11篇文体正式程度渐次降低的英语语料, 发现后者的代词分布数量是前者的10余倍, “ 小说中人称代词和物主代词满目皆是, 在许多科技文献中它们却寥若星辰” [14]。
| 表5 DWDS-Kernkorpus语料库中不同文体的名词占比 |
此外, 信息类文体, 特别是应用文、学术论文有一定的专业性和目标指向, 为了确保语义精确, 需要较多使用概念等专有名词。我们观察到, 专有名词在德语不同文体中的比例差异确实较大:在信息类文体中是5.38%, 而在想象类文体中是3.26%, 与Hudson的结果(信息类文体5%, 想象类文体4%)基本一致, 支持了Biber等[15]的研究结论, 即信息类文体特别是科学论文中专有名词占有突出地位。
在本部分开头我们曾提到, Tü Ba-D/Z语料库中各个名词子类的占比与其他三个语料库中的占比差异较大, 并猜测是不同的文体特征导致了这一差异。为了验证这一猜测, 我们对Brown语料库、LOB语料库以及DWDS-Kernkorpus语料库中报刊文章中的名词占比进行了单独统计。如表6所示, Tü Ba-D/Z语料库中各个名词子类的比例与其他三个语料库中的媒体类语料(报刊文章)相比不再有显著差异。由此可以证实名词子类占比的差异确实是由不同的文体特征所决定的。
| 表6 四个语料库中媒体类语料的名词占比 |
其实, 报刊中专有名词使用频率高, 是有其特殊原因的。正如魏欣欣和林大津对英语新闻用词特点的研究所显示的, 报刊的读者群较为宽泛, 文化程度高低不一, 这就要求记者尽量使用大多数人能理解而又生动形象的词语。其中较有效的手段之一是“ 经常在新闻报道中借用各国首都或大城市等地名、政府首脑名称、标志性建筑物名称, 来指代该国或其政府及有关机构” [16]87。
综上, 与前人研究的结论一致[3]2, 德语名词的占比与文体相关。此外, 本文基于大型语料库的研究还发现, 普通名词、专有名词和代词这三类词在德语不同文体中的占比与在英语的相应文体中的占比基本相同, 显然, 文体对名词分布的影响也是自然语言的普遍规律。
四、 名词分布与时间的关系
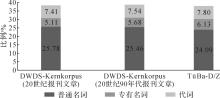
在表6中我们看到, 在对媒体类文章中的名词占比进行单独统计时, 各个语料库之间的数据差异有所减小。尽管如此, 差异仍然存在。由于各个语料库所收录文章的生成时间不同, 我们无法排除语言历时性发展对名词所占比例的影响。为了进一步考察时间因素对这一问题的影响, 我们专门提取出DWDS-Kernkorpus与Tü Ba-D/Z中同一时期即20世纪90年代的报刊文章, 将其与DWDS-Kernkorpus语料库所有时期报刊文章中的名词占比进行对比, 其结果如图1所示。
 | 图1 德语名词在20世纪90年代报刊文章(中、右)和20世纪所有报刊文章(左)中的占比 |
我们发现, DWDS-Kernkorpus、Tü Ba-D/Z所收录的20世纪90年代的报刊文章中名词各个子类占比之和分别为38.68%、38.02%, 均接近整个20世纪报刊文章的名词占比38.3%。从这一方面来看, 我们无法得出时间因素对名词占比有影响的结论。另一方面, 通过对普通名词、专有名词和代词三个名词子类占比的分布情况进行观察可以得出, DWDS-Kernkorpus所收录的20世纪90年代的报刊文章中普通名词和专有名词的比例25.46%、5.68%和整个20世纪报刊文章这两个子类的比例25.78%、5.11%基本一致, 而代词的比例也较为接近, 这一特征与Tü Ba-D/Z中的情况一致。由此, 在对20世纪报刊语料研究的基础上, 可以得出名词占比的历时性变化没有显著性差异的结论。
这是否与20世纪90年代本身就是20世纪的一部分有关?我们的研究是否应该在更广阔的历史维度中进行?为了进一步研究名词占比的历时性变化, 我们又考察了一个时间跨度为500年的大型语料库, 即DTA①(① http://www.deutschestextarchiv.de/, 2019 -09 -02.)。DTA语料库是历史语料篇章语料库, 收录了1473— 1969年间共3 527篇语料, 包含与DWDS-Kernkorpus语料库对应的四种文体(文学作品、应用文、学术论文和报刊文章), 总计词数约1.5亿(不含标点, 156 446 847单词)。我们在统计DTA语料库的名词占比时, 排除了124篇没有进行文体标记的语料和427篇外来词比例过高(大于5%)的文章, 最终用于统计的语料共2 976篇, 单词量约1.33亿。按照50年一个时段, 对1500— 1949年共9个时间段的名词占比进行了统计, 结果如图2所示。
图2显示, 16— 20世纪, 名词的总体比例基本保持不变, 始终在35%到40%之间, 但名词各个子类的占比呈现出明显的历时性变化。具体来说, 普通名词的占比在过去的5个世纪中持续增长, 从16世纪初的约14%增加到20世纪的约25%; 与此同时, 代词的占比持续降低, 从约17%下降到了约10%; 而专有名词的比例变化微小。
 | 图2 DTA语料库16— 20世纪名词占比历时变化 |
关于(德语)名词内部各子类间的这一动态历时性变化, 目前国内外均尚未有文献提及, 是本文的新发现。这一变化应源于社会形态、科学技术和语言本身的发展。随着社会关系日益复杂, 新生事物增多, 人们对客观世界的认知不断加深且更加精准, 人们在运用语言进行交流时对普通名词的需求也逐渐增加。《杜登词典》1880年首次出版时有27 000个词条, 如今已增加到145 000个。2017年第27版与2013年第26版相比, 新增从时事、科技、生活和口语中吸收的新鲜词5 000个, 其中绝大部分是名词①(① https://www.duden.de/presse/5-000-Woerter-staerker-Der-neue-Duden-ist-da, 2019-09-05.)。
与此同时, 随着政治、经济、科技、教育、文化等领域的发展, 总体来说, 德语呈现出简单、经济与实用的发展趋势[17]178187。一方面, 人们在语言使用上追求“ 语言经济性原则” ; 另一方面, 德语书面语出现了越来越多的口语特征[18]377。德语本身出现了一些变化, 比如:二格使用减少, 二格由复合词替代; 复合词增多, 替代关系从句; 分词短语或名词化结构替代从句表达增多[19]25; 句子变短、从句减少[18]377; 名词化结构增多的趋势明显[20]212。这些变化均直接导致代词的减少。或许这一变化不是德语的独特发展规律, 而是与名词占比一样, 具有跨语言的普遍性。未来我们将通过对其他语言的历史语料库进行研究来验证上述假设。
上述研究是基于DWDS-Kernkorpus和Tü ba-D/Z语料库收录的20世纪报刊文章, 从中并没有得出名词占比具有历时性变化这一结论, 因此, 我们提取DTA语料库中的报刊类文章进行专门研究。鉴于DTA语料库中1700年前的报刊文章数量很小(仅5篇), 可以忽略不计, 我们只对18— 20世纪的语料进行了研究, 其名词比例统计结果如图3所示。
 | 图3 DTA语料库17— 20世纪报刊文章中名词占比历时变化 |
结果显示, DTA语料库中报刊文章中的名词比例呈现出与整个语料库类似的历时性变化趋势。同时, 名词各个子类的占比也体现出显著的文体特征, 即报刊文章中普通名词和专有名词相对于其他文体的比例较高, 这与上文对DWDS-Kernkorpus进行研究得出的结论一致。由此可见, 时间因素与文体类型均对名词各个子类的占比有显著影响, 但名词的总体比例并未受二者影响。换言之, 跨越500年的数亿真实语料告诉我们, 名词分布可能真的就是人类语言的一个不变量, 但与此同时, 不变中也蕴含着变化。这种变与不变之间的交互作用恰好体现了人类语言作为一种人驱复杂适应系统的特质[21]。
五、 结语
本文以Hudson对英语中名词占比的研究、Liang和Liu对包括汉语在内的多种语言中名词占比的研究为出发点和研究范式, 对德语书面语的名词占比进行了计量研究。通过对德国柏林— 勃兰登堡科学院的大型语料库DWDS-Kernkorpus、DTA以及图宾根依存树库Tü Ba-D/Z进行分析, 得出如下结论:首先, 德语书面语中的名词所占比约为38%, 尽管德语复合名词比例高、名词化结构多, 但其名词占比同英语以及其他语言中的名词占比大致相符, 从而进一步证实了人类自然语言中名词占比具有普遍规律这一结论; 其次, 不同文体中名词及其各子类的占比有所差异, 而这一差异由文体特征所决定, 并且具有跨语言的相似性; 最后, 我们在对过去几个世纪的语料进行研究的基础上, 得出了时间因素与文体类型均对名词各个子类占比有显著影响, 但名词总体比例未受二者影响的结论。综上, 我们可以认为, 名词分布是人类语言的不变量。名词内部普通名词的比例不断上升, 而代词比例逐渐下降这一新发现, 则有待深入研究。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|